If you’ve created a chatbot that uses Retrieval Augmented Generation (RAG) you’ve probably come across RAG Fusion - a method advertised to improve the performance of such chatbots. In theory using Reciprocal Rank Fusion (RRF) to improve retrieval in RAG makes complete sense. However, there are cases where this approach doesn’t really fit into a production system.
What is RAG?
Retrieval Augmented Generation is a technique used to improve the accuracy of LLMs by providing them with an external knowledge base for response generation. While processing the user’s query, relevant information is retrieved from this external data source and passed to the LLM as a source of truth for generating the response. The data source is generally divided into documents and stored in a vector database as embeddings.
What is RRF?
Reciprocal Rank Fusion is a simple method of combining ranked list of entities retrieved from different sources.
Formally the RRF score can be calulated as follows:
$$\text{RRF}(i) = \sum_{r \in R} \frac{1}{k + r(i)}$$
where:
- $( R )$ is the set of ranking sources.
- $( r(i) )$ represents the rank position of item $( i )$ in ranking source $( r )$.
- $( k )$ is a constant (typically set to 60) to prevent dominance by top-ranked items.
Here is a more visual example:
The image shows three different lists being fused into a single ranked list using RRF. $R(i)$ represents the rank position of item $( i )$ with each color representing a unique document.
RRF + RAG = RAG Fusion
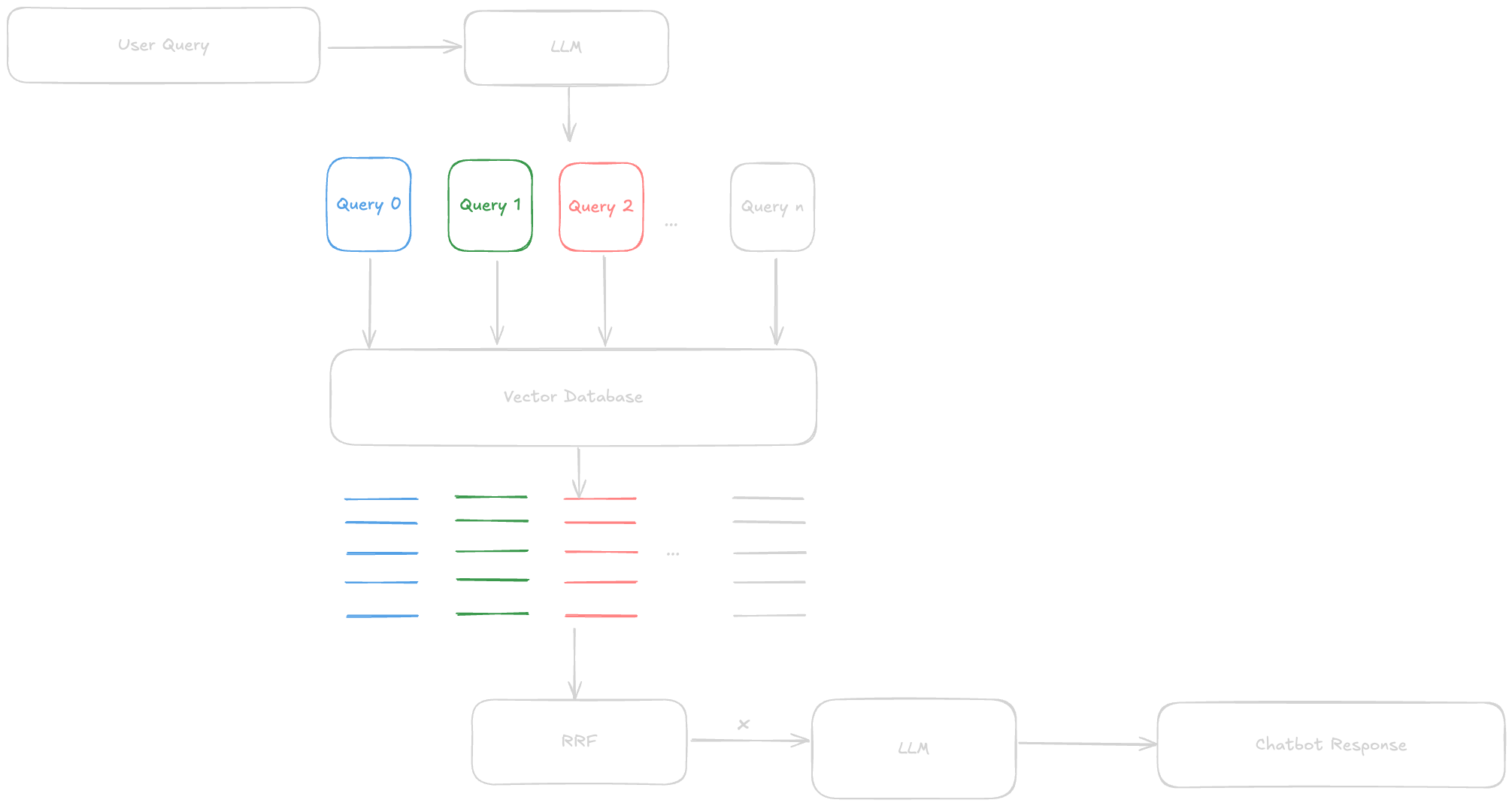
After the hype generated by vanilla RAG, researchers started looking into methods to improve retrieval in RAG pipelines. This led to the creation of RAG Fusion a method that incorporates RRF into RAG pipelines. A RAG pipeline however, doesn’t have multiple retrieval systems, so how does this actually work? An LLM is used to generate n more search queries from the user’s query.
The flow is somewhat like this:
- For every incoming user query, an LLM is asked to generate
nmore search queries. - The user’s query along with these
ngenerated queries are used to retrieve documents from the vector database. n+1ranked lists of documents retrieved from the vector store are combined using RRF.- Finally, the top
xdocuments are passed to an LLM for generating the response.
This is the prompt used in the original rag-fusion repo:
System Message:
You are a helpful assistant that generates multiple search queries based on a single input query
---
User Messages:
Generate multiple search queries related to: {user_query}
OUTPUT (4 queries):
Example alternate queries generated using this prompt:
Input User Query: impact of climate change
LLM Generated Ouput:
1. How does climate change affect global weather patterns?
2. Economic consequences of climate change on agriculture
3. Impact of climate change on biodiversity and ecosystems
4. Health risks associated with climate change
This post is highlights the impact of RAG Fusion on chatbot and chatbot like question answering systems. For all the experiments in this post I will be using the same prompt with GPT-4o.
How does this improve retrieval?
In theory, the LLM generated queries are expected to fetch documents that the user’s query on its own might have otherwise missed. In other words, these n alternate queries further explore the embedding space of the data source to find more relevant documents.
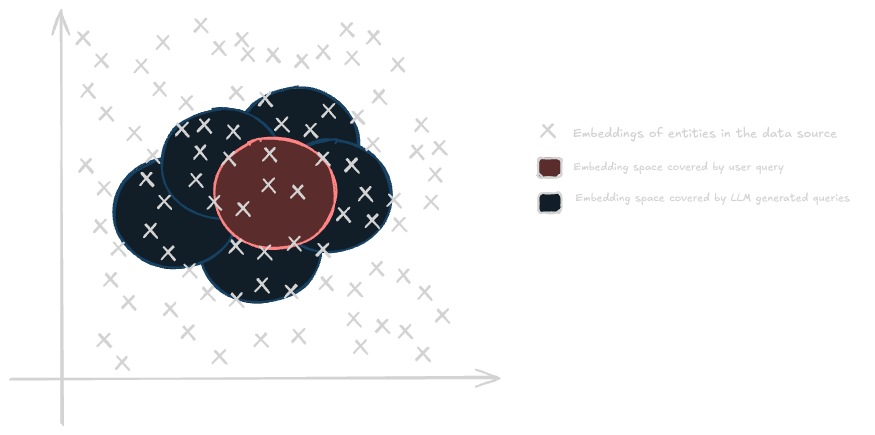
This diagram shows how all the queries combined cover more embedding space than the user’s query alone. Yes, this is an oversimplified 2 dimensional version of an embedding space, but you get the point.
What changes in production systems?
In a production system, performance improvements cannot come at the cost of consistency. If a user asks a chatbot the same question multiple times, it is expected to give the same answer every time. Sure it might not always have the same wording, but the core answer or logic of the answer should remain consistent. In other words a chatbot is expected to maintain consistency in its responses, unless there is a change in the data source. Once it answers a question, it cannot go back and say “I don’t know” or give a completely different answer when the same question is asked again.
Now here comes the tricky part, if search queries are generated using an LLM, achieving consistency becomes almost impossible. More so if the data source has large amount of documents for distinct topics. The main problem with how RAG Fusion is evaluated for chatbots is that the consistency of the system is never taken into account. In addition to this, the evaluations don’t account for any form of conversation the user might’ve had with the chatbot. Conversations are an important aspect of a chatbot interaction and in a production setup they look somewhat like this:
User: I purchased a game yesterday, but it’s not showing up in my library. What should I do?
---
Support Bot: I’m sorry for the inconvenience!
Please ensure you’re logged into the correct account.
If you are, try refreshing your library or restarting your device.
Let me know if the issue persists.
---
User: Why is this happening?
This example conversation between a user and an LLM based support bot shows how humans use anaphoric references in their conversation. An LLM can decode these references provided it has access to the conversation, this is a common NLP task called coreference resolution. Simply put, figuring out what this means in “Why is this happening?” is coreference resolution. For the alternate query generation to work in such cases, some part of the conversation (can be a summary) has to be passed to the LLM. Since, conversation representation are non-deterministic the same conversation might be summarized differently or the same question can be asked differently across interactions. This non-deterministic representation leads to unstable query generation.
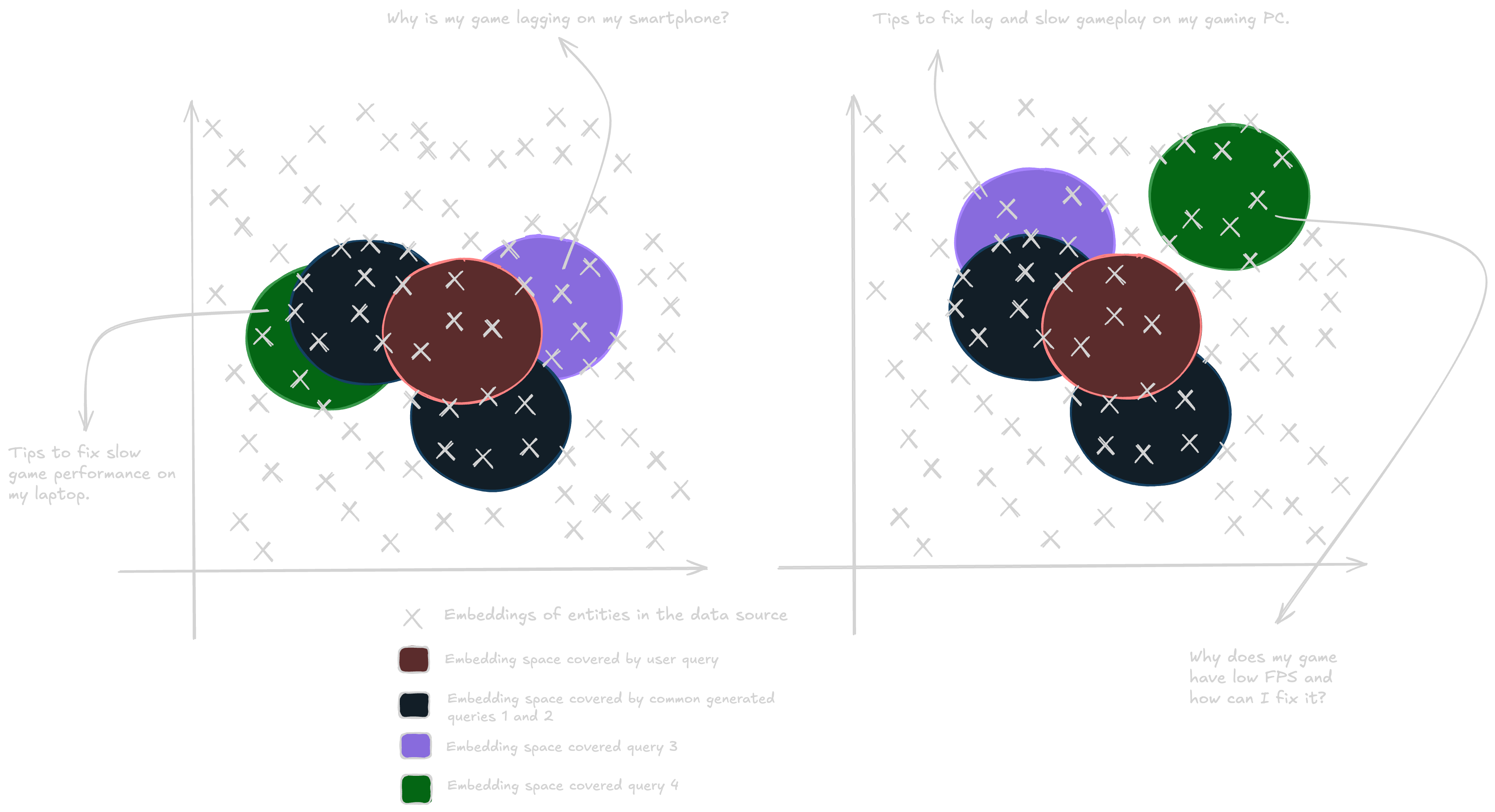
Okay, but how is instability in query generation linked to consistency? Different queries fetch different ranked documents from the vector database. These ranked documents when fused using RRF generate a complete different ranked list, leading to a completely different answer. Here is a more visual representation of how slight query changes can result in retrieval of completely different documents from the vector database:
Since chatbots are not the only application of RAG let’s forget about conversation history for a moment. Let’s assume a naive question answering system that doesn’t support follow-up questions. In this system if the user’s question is too broad, the LLM may tail towards a different interpretation of the question every time it is asked to generate the alternate queries. Sticking with the example of the game support bot, if the user asks a question like “Why is my game slow?” the LLM is forced to consider multiple aspects of the query, such as “which game”, “which platform”, “is this a hardware issue?”, or “is this a problem with the game itself?”.
Here are two sets of alternate queries 4o generated for the question:
SET 1:
1. What causes video games to run slowly on my computer?
2. How can I improve the performance of my game on my console?
3. Why is my game lagging on my smartphone?
4. Tips to fix slow game performance on my laptop.
SET 2:
1. What causes video games to run slowly on my computer?
2. How can I improve the performance of my game on a console?
3. Tips to fix lag and slow gameplay on my gaming PC.
4. Why does my game have low FPS and how can I fix it?
On comparing the two sets it can be observed that the last two queries are significantly different. Even at temperature 0, the LLM has to make choices about how to interpret the question. While it will always choose the most likely interpretation, there might be several close “most likely” interpretations. Subtle variations in the response generation process could tip the balance between these very close interpretations, leading to different sets of alternate questions.
The same problem is encountered, if the wordings of the query are changed slightly. Instead of “Why is my game slow?” if the query is changed to “My game is slow” the following alternate queries are generated:
1. Why is my game running slow on PC?
2. How to fix lag in video games?
3. Troubleshooting slow game performance on console
4. Tips to improve game speed on laptop
The ordering generated by queries in Set 1 might have a document about fixing slow gameplay in smart phones, while Set 2 might not talk about this at all.
This effect is noticeable in cases where the data source has large amount of documents for distinct topics. On top of this, if there are conflicting documents in the data source, things go south really fast. Imagine asking a question twice and getting two conflicting answers as response.
Finally, what happens if there aren’t a lot of documents available for distinct topics? Although this is quite rare, the LLM might generate queries that drift away from the main topic. Since the LLM isn’t aware of the depth of information covered by each topic it might generate a query which cannot be answered using the information in the data source. This drifter query might retrieve documents from a completely different topic. Leading to an inaccurate or hallucinated responses.
This particular scenario highlights an important limitation of RRF. RRF only considers the positions of documents in the ranked list and not their actual similarity scores with the query. For example, a document might be ranked 1st for a query, but with an extremely low similarity score of 0.15, indicating poor relevance (on a scale of 0-1). RRF would still assign it a high RRF score based solely on its position, potentially selecting irrelevant documents for final response generation. Let’s go back to our example of the gaming support bot:
If a user asks: "why my game keeps crashing after the latest update."
With limited documents, the generated queries might produce the following results:
Original: "why my game keeps crashing after the latest update"
→ retrieves Doc A (score: 0.78), Doc B (score: 0.65)
Generated: "troubleshooting game crashes following recent patches"
→ retrieves Doc A (score: 0.72), Doc C (score: 0.63)
Generated: "how to fix game instability issues after updates"
→ retrieves Doc D (score: 0.67), Doc E (score: 0.61)
Generated: "software conflicts causing game failures"
→ retrieves Doc F (score: 0.31), Doc G (score: 0.28)
Generated: "memory problems in gaming applications"
→ retrieves Doc H (score: 0.22), Doc I (score: 0.19)
RRF would assign Doc Hs #1 position the same weight as Doc D’s #1 position, despite Doc H having a relevance score of only 0.22 compared to Doc D’s 0.67. This means documents barely-relevent or even irrelevant will be given similar importance as documents specifically addressing game crashes after updates. When these documents are provided to the LLM, this irrelevant information can lead to generic advice if the LLM is smart enough or it can also lead to hallucination.
Restrictions can be added to the prompt in order to minimize the generation of drifter queries, but these restrictions may sometimes come at the cost of creativity. The generated queries can become too similar to the user’s input, making them more likely to retrieve the same documents from data sources. Thus, effectively nullifying the whole purpose of generating these alternate queries. Unfortunately, for a production system, in a tradeoff between consistency and creativity, consistency wins.
Should I not use RAG Fusion?
The answer to this question is not straightforward as it depends on the use case, data source, chunking strategy, embedding model and many other things in the pipeline. The best way to figure out what works is to experiment. Experiment with each and every configurable parameter in the pipeline to figure out what works best for the given data source. There may be a case where the data source has just the perfect amount of data for distinct topics. RRF might significantly improve retrieval in this case. If not, you can also try alternatives like HYDE or even fine tuning.
At r2decide after a lot of experimentation we realized that RAG Fusion was not the right approach for our system. Instead, switching to a simpler 2-step setup that performs coreference resolution using an LLM, followed by semantic reranking using a reranker yields better results. Coreference resolution refines the user’s query, while the reranker helps determine which retrieved documents are most important. This approach is a bit faster and cost effective as the number of queries being executed on the vector database are significantly low. Although, LLMs are not perfect at co-reference resolution, the pipeline is more stable and consistent compared to the RAG Fusion approach.
Conclusion
RAG Fusion can improve retrieval in some cases, but it may not suit production systems focused on consistency. The world of Generative AI is progressing at an insane rate and I can barely keep up. However, take all the cool shit that you see with a grain of salt. What works for one use case might not work for another. The only way to find out what works for you is to experiment.
Special thanks to Yogesh and Hansal who did a lot of the ground work related to this problem and thanks to Allen for reviewing drafts of the post.
Bibliography
Original Paper on RRF: https://doi.org/10.1145/1571941.1572114
Blog Post that Introduced RAG Fusion: https://medium.com/towards-data-science/forget-rag-the-future-is-rag-fusion-1147298d8ad1
Paper on RAG Fusion: https://arxiv.org/abs/2402.03367